

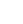

 Abstract
Abstract HTML
HTML Reference
Reference Related
Related PDF
PDF










-
Heavy-ion collisions at relativistic energies produce matter at extreme energy density and temperature conditions. This matter is likely to comprise deconfined quarks and gluons and is called quark-gluon plasma (QGP). A primary objective of heavy-ion collision experiments is to explore the phase structure of the hot dense QCD matter. The QCD phase structure can be expressed as a function of temperature (T) and baryon chemical potential (
$ \mu_{{\rm{B}}} $ ) [1]. QCD based model calculations predict that at large$ \mu_{{\rm{B}}} $ values, the transition from hadronic matter to QGP is of the first order [2, 3]. The end point of the first order phase transition boundary is known as the QCD critical point (CP), after which there is no genuine phase transition, except a smooth crossover from hadronic to quark-gluon degrees of freedom [4, 5]. One of the major approaches to exploring the QCD phase structure is via the measurements of event-by-event fluctuations of conserved quantities, such as net-baryon (B), net-charge (Q) and net-strangeness (S) [6-10]. In a thermodynamic system, r-th order fluctuations ("cumulants") of event-by-event net-multiplicity distributions are related to the r-th order thermodynamic susceptibilities of the corresponding conserved charges that diverge near the critical point [11-14]. Furthermore, these measured cumulants have also been used to extract freeze-out parameters (T and$ \mu_{\rm{B}} $ ) by comparing them with model calculations from lattice QCD and hadron resonance gas (HRG) [15-19]. Owing to the experimental constraints on measuring neutral particle yields, net-proton and net-kaons are adopted as experimental proxies of net-baryon and net-strangeness, respectively. In the last decade, the STAR and PHENIX experiments at the relativistic heavy ion collider (RHIC) have measured the second, third, and forth order cumulants of net-proton [20-24], net-charge [25, 26] and net-kaon [27] multiplicity distributions over a wide range of collision energies to determine non-monotonic energy dependence behaviours, as an indicator of the CP presence. Within current statistical uncertainties, no distinctive signatures of the CP have been inferred from the net-charge and net-kaon measurements. However, recent measurements of forth order to second order cumulant ratios of net-proton multiplicity distributions exhibit non-monotonic energy dependence as a function of$ \sqrt {{s_{\rm{NN}}}}$ [23]. Although, before drawing any substantial physics conclusion from event-by-event fluctuation measurements, we need to carefully investigate the different background contributions [28-33].Recently, the STAR experiment reported the first measurement of second-order mixed-cumulants between net-charge, net-proton, and net-kaon multiplicity distributions in the first phase of the beam energy scan (BES-I) program at RHIC [34]. These mixed-cumulants are related to the off-diagonal thermodynamic susceptibilities that carry the correlation between different conserved charges of QCD [35-41]. The importance of the second-order mixed-cumulants was first highlighted in the context of normalized baryon-strangeness susceptibilities (
$ C_{B,S} = -3\chi^{1,1}_{B,S}/\chi^2_{S} $ ) in Ref. [35], which are expected to exhibit a rapid change with the onset of deconfinement. These quantities can be investigated by measuring the energy dependence ratios of off-diagonal over diagonal cumulant ratios between net-baryon and net-strangeness ($ C^{1,1}_{B,S}/C^{2}_{S} $ ). Another research objective originates from the comparisons between the ideal HRG model and lattice QCD calculations. The baryon-charge susceptibility ($ \chi^{1,1}_{B,Q} $ ) exhibits a significant difference between the lattice and ideal HRG calculations above the crossover transition temperature, even in at the lowest order [42, 43]. A similar difference between the lattice and HRG calculations can also be observed in higher-order baryon susceptibilities (($ \chi^{4}_B $ )), which is more statistically challenged in the experimental measurement [44]. Similar to diagonal cumulants, the mixed-cumulants are also limited by the lack of neutral particle detection capability. The measurements of charge-baryon or charge-strangeness mixed-cumulants are less affected by such an experimental limitation, as the neutral particles do not contribute to such charge correlations, and can be approximated by$ C^{1,1}_{Q,B} \approx C^{1,1}_{Q,p} $ and$ C^{1,1}_{Q,S}\approx C^{1,1}_{Q,k} $ [40]. In contrast, baryon-strangeness mixed-cumulants cannot be approximated by the proton-kaon off-diagonal. However, the relationship between these cumulants have been studied in Refs. [40, 45].Recent measurements of second-order mixed-cumulants at the RHIC energy range (
$ \sqrt {{s_{{\rm{NN}}}}}\; $ = 7.7-200 GeV) agree well with different model predictions for the net proton-kaon off-diagonal correlator ($ C_{p,k} = $ $ \sigma^{1,1}_{p,k}/\sigma^{2}_{k} $ ). However, the charge-proton ($ C_{Q,p} = \sigma^{1,1}_{Q,p}/\sigma^{2}_{p} $ ) and charge-kaon ($ C_{Q,k} = \sigma^{1,1}_{Q,k}/\sigma^{2}_{k} $ ) correlators significantly deviate from the model predicted values. In this study, we demonstrate that the deviations observed in charge-proton and charge-kaon correlators are owing to the efficiency double counting. We argue that, to correct the effects of efficiency for the charge-proton and charge-kaon mixed-cumulants, the particle identification for charge needs to be performed with the estimation of corresponding efficiencies. However, a significant number of charged tracks are missed for particle identification as different detectors used [34]. In this study, we focus on the 2nd-order mixed-cumulant for two variables to elucidate and simplify several important points on the efficiency correction. Although the points also apply for higher-order mixed-cumulants, including more than two variables cases, these extensions should be straightforward and are expected to be investigated in future studies.This paper is organized as follows. In Sec II, cumulants, mixed-cumulants, and their efficiency corrections are introduced. The formulas for the efficiency correction of the 2nd-order mixed-cumulant is discussed for two types of correlations. In Sec. III, we perform numerical analysis using the UrQMD model to verify the importance of adopting appropriate formulas, depending on the correlation type. Here, the effects of double-counting are discussed, and the potential effects of the multiplicity loss owing to particle identification are investigated. Finally, we summarize this study in Sec. IV.
-
In statistics, any distribution can be characterized by different order moments or cumulants. The rth-order moment of variable N is defined by the rth order derivative of moment generating function
$ G(\theta) $ :$ G(\theta) = \sum\limits_{N}{\rm e}^{N\theta}P(N) = {\langle{{\rm e}^{N\theta}}\rangle} , $

(1) $ {\langle{N^{r}}\rangle} = \frac{{\rm d}^{r}}{{\rm d}\theta^{r}}G(\theta)\Bigl|_{\theta = 0}, $

(2) where
$ P(N) $ is a probability distribution function, and$ {\langle{\cdot}\rangle} $ represents an average over events. Cumulants are defined by the cumulant generating function$ T(\theta) $ , which is the logarithm of moment-generating function:$ T(\theta) = {\rm{ln}}G(\theta), $

(3) $ {\langle{N^{r}}\rangle} _{\rm{c}} = \frac{{\rm d}^{r}}{{\rm d}\theta^{r}}T(\theta)\Bigl|_{\theta = 0}, $

(4) where
$ {\langle{\cdot}\rangle} _{\rm{c}} $ represents the cumulant of the variable inside the bracket.From Eqs. (1)–(4), the 1st and 2nd-order cumulants are expressed in terms of moments
$ {\langle{N}\rangle} _{\rm{c}} = {\langle{N}\rangle} , $

(5) $ {\langle{N^{2}}\rangle} _{\rm{c}} = {\langle{N^{2}}\rangle} - {\langle{N}\rangle} ^{2}, $

(6) Similarly, the multivariate moments and cumulants are defined by the multivariate generating function. In this study, we focus on the two-variable case, which we call "mixed-" moments or cumualnts, where the moment generating function is given by
$ G(\theta_{1},\theta_{2}) = \sum\limits_{N_{1},N_{2}}{\rm e}^{\theta_{1}N_{1}}{\rm e}^{\theta_{2}N_{2}}P(N_{1},N_{2}) = {\langle{{\rm e}^{\theta_{1}N_{1}}{\rm e}^{\theta_{2}N_{2}}}\rangle} , $

(7) $ {\langle{N_{1}^{r_{1}}N_{2}^{r_{2}}}\rangle} = \frac{\partial^{r_{1}}}{\partial\theta_{1}^{r_{1}}}\frac{\partial^{r_{2}}}{\partial\theta_{2}^{r_{2}}} G(\theta_{1},\theta_{2})\Big|_{\theta_{1} = \theta_{2} = 0}. $

(8) Mixed-cumulants are then defined as
$ T(\theta_{1},\theta_{2}) = {\rm{ln}}G(\theta_{1},\theta_{2}), $

(9) $ {\langle{N_{1}^{r_{1}}N_{2}^{r_{2}}}\rangle} _{\rm{c}} = \frac{\partial^{r_{1}}}{\partial\theta_{1}^{r_{1}}}\frac{\partial^{r_{2}}}{\partial\theta_{2}^{r_{2}}} T(\theta_{1},\theta_{2})\Big|_{\theta_{1} = \theta_{2} = 0}. $

(10) From Eqs. (7)–(10), we obtain the 2nd-order mixed-cumulant in terms of moments and mixed-moments:
$ {\langle{N_{1}N_{2}}\rangle} _{\rm{c}} = {\langle{N_{1}N_{2}}\rangle} - {\langle{N_{1}}\rangle} {\langle{N_{2}}\rangle} . $

(11) -
The particle detection efficiency of each detector is always limited. The event-by-event particle multiplicity distributions are convoluted owing to this finite detector efficiency. The efficiency correction needs to be performed to recover the true multiplicity distribution. For simplicity, we assume that the detection efficiency can be approximated by the binomial efficiency response function [46, 47]. The mean value (first-order moment/cumulant) can be easily reconstructed by division with the binomial efficiency response; however, its influence on higher-order cumulants is complicated and depends on the probability distribution of efficiency [48-50]. Throughout this paper, we focus on a simple assumption of the binomial distribution given by
$ \tilde{P}(n) = \sum\limits_{N}P(N)B_{\varepsilon,N}(n), $

(12) $ B_{\varepsilon,N}(n) = \frac{N!}{n!(N-n)!}\varepsilon^{n}(1-\varepsilon)^{N-n}, $

(13) where
$ \varepsilon $ represents the efficiency, while N and n are generated and measured particles, respectively. In this case, the correction formulas can be derived in a straightforward manner, as discussed in the literature [46, 47, 51-56]. The efficiency correction for the 2nd-order mixed-cumulant is given by [55, 56]$ {\langle\!\langle{ K_{(x)}K_{(y)} }\rangle\!\rangle} _{\rm{c}} = {\langle{\kappa_{(1,0,1)}\kappa_{(0,1,1)}}\rangle} _{\rm{c}} + {\langle{\kappa_{(1,1,1)}}\rangle} _{\rm{c}} - {\langle{\kappa_{(1,1,2)}}\rangle} _{\rm{c}}, $

(14) with
$ K_{(x)} = \sum\limits_{i}^{M}x_{i}n_{i},\quad K_{(y)} = \sum\limits_{i}^{M}y_{i}n_{i}, $

(15) $ \kappa{(r,s,t)} = \sum\limits_{i = 1}^{M}\frac{x_{i}^{r}y_{j}^{s}}{\varepsilon_{i}^{t}}n_{i} , $

(16) where
$ {\langle\!\langle{\cdot}\rangle\!\rangle} $ represents the efficiency correction, M is the number of efficiency bins,$ n_{i} $ indicates the number of particles,$ \varepsilon_{i} $ is the efficiency,$ x_{i} $ and$ y_{i} $ are the electric charges of the particles at the ith efficiency bin. Notably, Eqs. (15) and (16) can be rewritten in track-by-track notations as$ K_{(x)} = \sum\limits_{j}^{n^{\rm{tot}}}x_{j},\quad K_{(y)} = \sum\limits_{i}^{n^{\rm{tot}}}y_{j}, $

(17) $ \kappa{(r,s,t)} = \sum\limits_{j = 1}^{n^{\rm{tot}}}\frac{x_{j}^{r}y_{j}^{s}}{\varepsilon_{j}^{t}}, $

(18) where
$ n_{\rm{tot}} = \sum_{i}^{M}n_{i} $ is the number of measured particles in one event, and the other variables are now track-wise with j running over the particles in the summation.In the rest of this section, we consider two efficiency bins for simplicity. Particles for each bin have the same efficiency values,
$ \varepsilon_{1} $ and$ \varepsilon_{2} $ , respectively. The number of particles will be denoted by$ n_{1} $ and$ n_{2} $ . -
Let's consider the correlation between two mutually exclusive variables. From Eq. (10), the mixed-cumulant of generated particles are expanded in terms of moments as
$ {\langle{N_{1}N_{2}}\rangle} _{\rm{c}} = {\langle{N_{1}N_{2}}\rangle} - {\langle{N_{1}}\rangle} {\langle{N_{2}}\rangle} . $

(19) To perform the efficiency correction relative to measured particles, we suppose
$ x = (x_{1},x_{2}) = (1,0), $

(20) $ y = (y_{1},y_{2}) = (0,1), $

(21) to consider
$ {\langle\!\langle{K_{(x)}K_{(y)}}\rangle\!\rangle} _{\rm{c}} $ with$ K_{(x)} = n_{1} $ and$ K_{(y)} = n_{2} $ . From Eq. (14), we get$ \begin{aligned}[b] {\langle\!\langle{ K_{(1,0)}K_{(0,1)} }\rangle\!\rangle} _{\rm{c}} =& {\langle{\kappa{(1,0,1)}\kappa{(0,1,1)}}\rangle} _{\rm{c}} + {\langle{\kappa{(1,1,1)}}\rangle} _{\rm{c}}\\& - {\langle{\kappa{(1,1,2)}}\rangle} _{\rm{c}} = {\Bigl\langle{\frac{n_{1}}{\varepsilon_{1}}\frac{n_{2}}{\varepsilon_{2}}}\Bigr\rangle} _{\rm{c}} \\ =& \frac{1}{\varepsilon_{1}\varepsilon_{2}}{\langle{n_{1}n_{2}}\rangle} - \frac{1}{\varepsilon_{1}\varepsilon_{2}}{\langle{n_{1}}\rangle} {\langle{n_{2}}\rangle} , \end{aligned} $

(22) which is the basic formula of the efficiency correction for the 2nd-order mixed-cumulant of two variables.
-
Next, we consider the correlation between
$ N_{1} $ and$ N_{1}+N_{2} $ , i.e, when the two variables are not mutually exclusive. It is clear that we have the self-correlation of$ N_{1} $ . The 2nd-order mixed-cumulant can be expanded as$ {\langle{N_{1}(N_{1}+N_{2})}\rangle} _{\rm{c}} = {\langle{N_{1}N_{2}}\rangle} - {\langle{N_{1}}\rangle} {\langle{N_{2}}\rangle} + {\langle{N_{1}^{2}}\rangle} - {\langle{N_{1}}\rangle} ^{2}, $

(23) where the last two terms represent the variance (2nd-order cumulant,
$ {\langle{N_{1}^{2}}\rangle} _{\rm{c}} $ ). If we employ Eq. (22) for the efficiency correction, we can just replace$ n_{1} $ to$ n_{1}+n_{2} $ as$\begin{aligned}[b] {\langle\!\langle{K_{(1,0)}K_{(0,1)}}\rangle\!\rangle} _{\rm{c}} =& \frac{1}{\varepsilon_{1}\varepsilon_{2}'}{\langle{n_{1}(n_{1}+n_{2})}\rangle} - \frac{1}{\varepsilon_{1}\varepsilon_{2}'}{\langle{n_{1}}\rangle} {\langle{n_{1}+n_{2}}\rangle} , \\ =& \frac{1}{\varepsilon_{1}\varepsilon_{2}'}{\langle{n_{1}n_{2}}\rangle} - \frac{1}{\varepsilon_{1}\varepsilon_{2}'}{\langle{n_{1}}\rangle} {\langle{n_{2}}\rangle} \\& + \frac{1}{\varepsilon_{1}\varepsilon_{2}'}{\langle{n_{1}^{2}}\rangle} - \frac{1}{\varepsilon_{1}\varepsilon_{2}'}{\langle{n_{1}}\rangle} ^{2},\end{aligned} $

(24) with
$ \varepsilon_{2}' $ being the averaged efficiency for$ N_{1} $ and$ N_{2} $ given by$ \varepsilon_{2}' = \frac{{\langle{N_{1}}\rangle} \varepsilon_{1}+{\langle{N_{2}}\rangle} \varepsilon_{2}}{{\langle{N_{1}}\rangle} +{\langle{N_{2}}\rangle} }, $

(25) which is not an appropriate efficiency corrected expression for mutually inclusive variables. To confirm this, we suppose that two independent variables
$ N_{1} $ and$ N_{2} $ follow the Poisson distribution with$ {\langle{N_{1}}\rangle} = 4 $ and$ {\langle{N_{2}}\rangle} = 6 $ . It is known that the relation$ {\langle{N^{r}}\rangle} _{\rm{c}} = {\langle{N}\rangle} _{\rm{c}} $ holds for Poisson distributions; thus,$ {\langle{N^{2}}\rangle} _{\rm{c}} = {\langle{N^{2}}\rangle} -{\langle{N}\rangle} ^{2} $ , which leads to$ {\langle{N_{1}(N_{1}+N_{2})}\rangle} _{\rm{c}} = 4 $ , from Eq. (23). The relationship$ {\langle{N_{1}N_{2}}\rangle} = {\langle{N_{1}}\rangle} {\langle{N_{2}}\rangle} $ was adopted for the independent variables. We then consider the efficiency correction for$ \varepsilon_{1} = 0.5 $ and$ \varepsilon_{2} = 0.4 $ . Accordingly,$ \varepsilon_{2}' = 0.44,\; {\langle{n_{1}}\rangle} = 2,\; {\langle{n_{2}}\rangle} = 2.4, $

(26) $ {\langle{n_{1}^{2}}\rangle} _{\rm{c}} = {\langle{n_{1}^{2}}\rangle} - {\langle{n_{1}}\rangle} ^{2} = 2, $

(27) $ {\langle{n_{1}n_{2}}\rangle} = {\langle{n_{1}}\rangle} {\langle{n_{2}}\rangle} , $

(28) which leads to the efficiency corrected mixed-cumulant value
$ {\langle\!\langle{K_{(1,0)}K_{(0,1)}}\rangle\!\rangle} _{\rm{c}} = 4.55. $

(29) Hence, Eq. (22) is not valid for the self correlated or mutually inclusive case.
-
The solution is to adopt the appropriate indices for x and y in Eqs. (16) and (15). To consider
$ {\langle\!\langle{K_{(x)}K_{(y)}}\rangle\!\rangle} _{\rm{c}} $ with$ K_{(x)} = n_{1} $ and$ K_{(y)} = n_{1}+n_{2} $ , the indices should have been$ x = (x_{1},x_{2}) = (1,0), $

(30) $ y = (y_{1},y_{2}) = (1,1), $

(31) thus
$ \begin{aligned}[b]{\langle\!\langle{ K_{(1,0)}K_{(1,1)} }\rangle\!\rangle} _{\rm{c}} =& {\langle{\kappa{(1,0,1)}\kappa{(0,1,1)}}\rangle} _{\rm{c}} \\&+ {\langle{\kappa{(1,1,1)}}\rangle} _{\rm{c}} - {\langle{\kappa{(1,1,2)}}\rangle} _{\rm{c}} \\ =& \frac{1}{\varepsilon_{1}\varepsilon_{2}}{\langle{n_{1}n_{2}}\rangle} - \frac{1}{\varepsilon_{1}\varepsilon_{2}}{\langle{n_{1}}\rangle} {\langle{n_{2}}\rangle} + \frac{1}{\varepsilon_{1}^{2}}{\langle{n_{1}^{2}}\rangle} \\&- \frac{1}{\varepsilon_{1}^{2}}{\langle{n_{1}}\rangle} ^{2} + \frac{1}{\varepsilon_{1}}{\langle{n_{1}}\rangle} - \frac{1}{\varepsilon_{1}^{2}}{\langle{n_{1}}\rangle} ,\end{aligned} $

(32) where we determine two additional terms compared with Eq. (24). It is inferred that the last four terms in Eq. (32) represent the efficiency correction of the variance (2nd-order cumulant),
$ {\langle\!\langle{K_{(x)}^{2}}\rangle\!\rangle} $ , which corresponds to the last two terms in Eq. (23) ①. This indicates that the variance term has to be correctly considered for the mutually inclusive variable case, which cannot be handled by Eq. (22).We summarize this section as follows. The efficiency correction formula for the 2nd-order mixed-cumulant was fully expanded for two cases: one is for two mutually exclusive variables, and the other case assumes that one variable is a subset of the other, to consider the self-correlation, as expressed in Eqs. (22) and (32). Both cases were determined to be incompatible with each other. The proper correction formulas needs to be obtained by substituting appropriate indices into Eqs. (14)–(16). This implies that the efficiency values have to be handled properly for each variable, without averaging them, especially when considering the self-correlation. It should be noted that the risk of using the averaged efficiency has already been pointed out in Ref. [55] for higher-order cumulants of single-variables. The efficiency bins always need to be carefully handled. The track-by-track efficiency via the identified particle approach expressed in Eqs. (17) and (18) would be a better way to handle all possible variations of efficiencies [56]. However, the particle identification needs to be applied to determine the efficiencies for different particle species, which does not discard a small amount of particles, depending on the overlapping area of the variables for the particle identification. This effect will be studied by numerical simulations in the next section [25, 57].
-
To validate the discussion from the previous section, we have analyzed the second-order mixed cumulants from the UrQMD event generator at
$ \sqrt {{s_{{\rm{NN}}}}}\; $ = 200 GeV. The UrQMD is a microscopic transport model, where the space-time evolution of the fireball is considered in terms of the excitation of color strings that fragment further into hadrons, the co-variant propagation of hadrons and resonances that undergo scatterings, and finally the decay of all the resonances [58, 59]. The collision energy dependence of the baryon stopping phenomenon is dynamically incorporated in the UrQMD model. The UrQMD model has been relatively successful and widely used in the heavy-ion phenomenology [59, 60]. Previously, this model was adopted to study several observable fluctuations and cumulants [28, 40, 61-65]. More information on the UrQMD model can be found in Refs. [58, 59]. In this study, we have adopted approximately one million events for Au+Au collisions at$ \sqrt {{s_{{\rm{NN}}}}}\; $ = 200 GeV to probe the efficiency correction effect on mixed cumulants. The obtained results are presented for 9 different centrality bins represented by the average number of participant nucleons (${\langle{N_{\rm part}}\rangle}$ ). In this study, we have applied the same kinematic acceptance$ |\eta|<0.5 $ and$ 0.4<p_{T}<1.6 $ GeV/c as STAR data [34]. The collision centrality is defined using RefMult2 (charged particle multiplicity within the pseudorapidity range$ 0.5<|\eta|<1.0 $ ) to reduce the centrality auto-correlation effect [28, 29]. Figure 1 illustrates the centrality dependence of second-order mixed-cumulants of net-charge, net-proton, and net-kaon multiplicity distributions from the UrQMD model. The gray solid points represent the 'true' mixed-cumulants values. To introduce the detector efficiency effect, we passed the binomial filter to the counted particles number in each event. We adopted two$ p_{T} $ -bin and positive-negative separate efficiencies, similar to real data analysis. We took this approach because different detector subsystems are used for particle identification in a high or low momentum region [34]. These subsystems have different efficiencies, and it is always better to use their proper efficiency values over their average efficiencies [55]. Subsequently, we estimated the mixed-cumulants with filtered particle numbers represented by red square points, which are analogous to efficiency uncorrected values.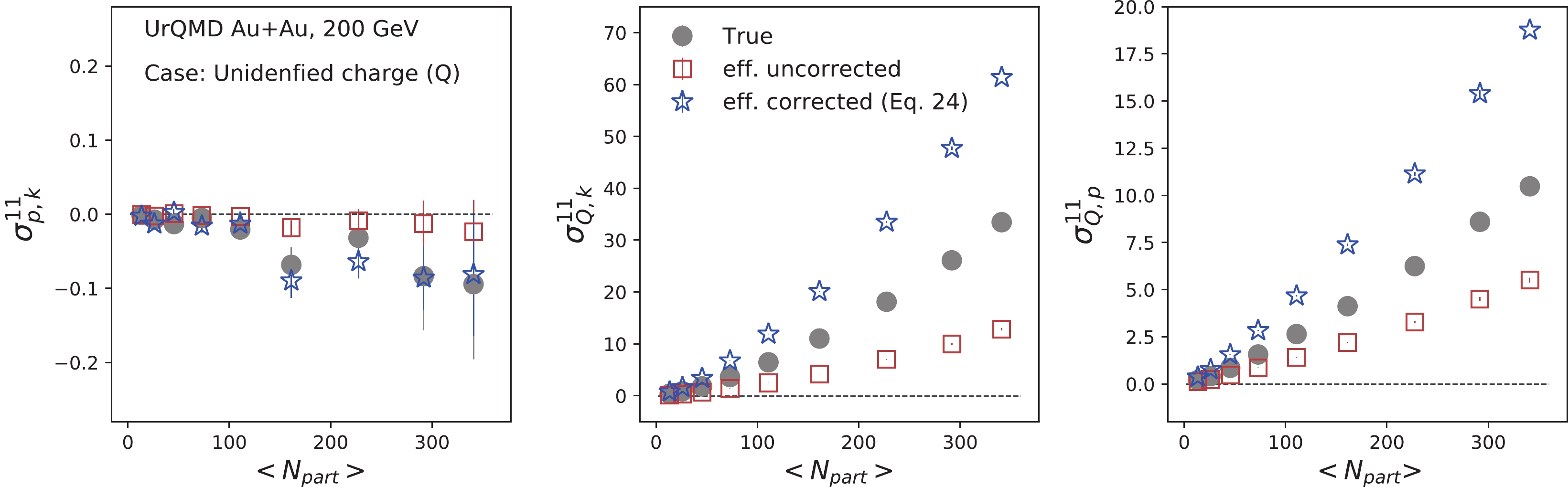
Figure 1. (color online) Centrality dependence of second-order mixed-cumulants of net-charge (
$ Q = N_{Q^{+}}-N_{Q^{-}} $ ), net-proton ($ p = N_{p}-N_{\bar{p}} $ ), and net-kaon ($ k = N_{k^{+}}-N_{k^{-}} $ ) multiplicities for Au+Au collisions at 200 GeV, using the UrQMD model. The efficiency corrections are performed assuming variables are mutually exclusive (Eq. (22)).In the next step, we correct the efficiency using input efficiency values. In this case, we adopted unidentified charged particles for the net-charge (Q), and applied Eq. (22), similar to the STAR measurement. The p-k mixed cumulant "true" value can be reproduced via this method, as they are mutually exclusive variables. However, the efficiency correction for Q-p and Q-k fails to reproduce the "true" values, as we discussed in Sec. II. We end up with a higher value for unidentified charge correlators. This leads to a higher value in cumulant ratios
$ C_{Q,k} = \sigma_{Q,k}/\sigma^{2}_{k} $ and$ C_{Q,p} = \sigma_{Q,p}/\sigma^{2}_{p} $ obtained from "true" values, as presented in Fig. 2. This shows that Eq. (22) is not valid for overlap or mutually inclusive variables. The observation is qualitatively consistent with the fact that$ C_{p,k} $ values in Ref. [34] agree well with model calculations, while$ C_{Q,k} $ and$ C_{Q,p} $ are significantly above the model calculations. However, for mutually exclusive variables (like protons-kaons), there is no issue. As we discussed before, to correct the mixed cumulant for mutually inclusive variables, Eq. (32) is required. To apply Eq. (32) for Q-k and Q-p mixed cumulants, it is necessary to identify the charged particles with their efficiencies. In Figs. 3 and 4, we solely consider identified charged particles ($ Q = \pi+k+p $ ). Then, Eq. (32) becomes
Figure 2. (color online) Centrality dependence of second-order off-diagonal to diagonal cumulant ratios for Au+Au collisions at 200 GeV, using the UrQMD model. The efficiency corrections are performed assuming the variables are mutually exclusive (Eq. (22)).
$ \begin{aligned}[b] {\langle\!\langle{N_{Q}N_{k}}\rangle\!\rangle} _{\rm{c}} =& {\langle\!\langle{(N_{\pi}+N_{p}+N_{k})N_{k}}\rangle\!\rangle} _{\rm{c}} \\ =& \frac{1}{\varepsilon_{1}\varepsilon_{3}}{\langle{N_{\pi} N_{k}}\rangle} - \frac{1}{\varepsilon_{1}\varepsilon_{3}}{\langle{N_{\pi}}\rangle} {\langle{N_{k}}\rangle} \\&+ \frac{1}{\varepsilon_{2}\varepsilon_{3}}{\langle{N_{p} N_{k}}\rangle} - \frac{1}{\varepsilon_{2}\varepsilon_{3}}{\langle{N_{p}}\rangle} {\langle{N_{k}}\rangle} \\& + \frac{1}{\varepsilon_{3}^{2}}{\langle{N_{k}^{2}}\rangle} - \frac{1}{\varepsilon_{3}^{2}}{\langle{N_{k}}\rangle} ^{2} + \frac{1}{\varepsilon_{3}}{\langle{N_{k}}\rangle} - \frac{1}{\varepsilon_{3}^{2}}{\langle{N_{k}}\rangle} , \end{aligned} $

(33) where
$ \varepsilon_{1} $ ,$ \varepsilon_{2} $ , and$ \varepsilon_{3} $ represent the efficiencies for pions, kaons, and protons, respectively. Now, we can reproduce the "true" values, as presented in Figs. 3 and 4.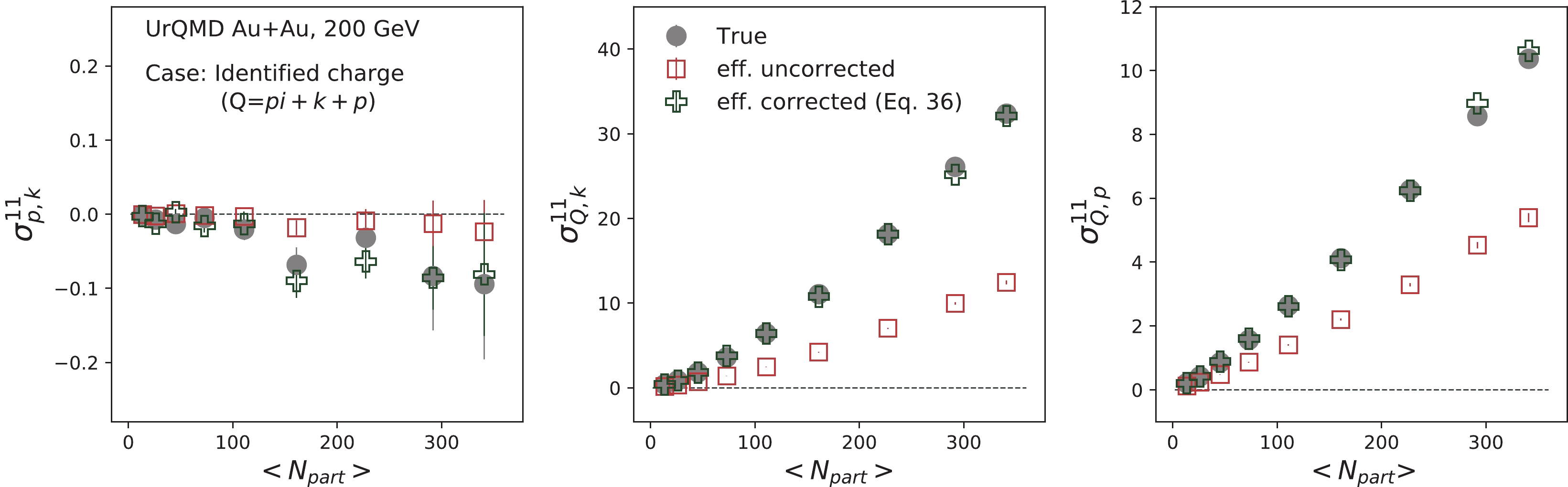
Figure 3. (color online) Centrality dependence of second-order mixed-cumulants of identified net-charge (
$ Q = (N_{\pi^{+}}+N_{k^{+}}+N_{p})- $ $ (N_{\pi^{-}}+N_{k^{-}}+N_{\bar{p}}) $ ), net-proton ($ p = N_{p}-N_{\bar{p}} $ ), and net-kaon ($ k = N_{k^{+}}-N_{k^{-}} $ ) multiplicity for Au+Au collisions at 200 GeV, using the UrQMD model. The efficiency corrections are performed assuming the variables are mutually inclusive (Eq. (32)).
Figure 4. (color online) Centrality dependence of second-order off-diagonal to diagonal cumulant ratios of identified charged particles for Au+Au collisions at 200 GeV, using the UrQMD model. The efficiency corrections are performed assuming the variables are mutually inclusive (Eq. (32)).
However, owing to the particle identification with optimal purity, we may lose a few pions, protons, and kaons. We also studied the effects of these tracks for mixed cumulants via UrQMD simulations. Charged particle identification is performed using the ionization energy loss inside the time projection chamber (TPC) detector subsystem. We mimic the ionization energy loss curve in UrQMD simulation using the STAR TPC resolution. Figure 5(a) presents the measured
${\rm d}E/{\rm d}x$ distribution after passing the UrQMD input through the TPC simulation. The measured values of${\rm d}E/{\rm d}x$ are compared to the expected theoretical values which is an extension of the Bethe-Bloch formula [66] (shown as dashed lines in Fig. 5(a)). To identify particles X, a quantity$ n\sigma_{X} $ is defined as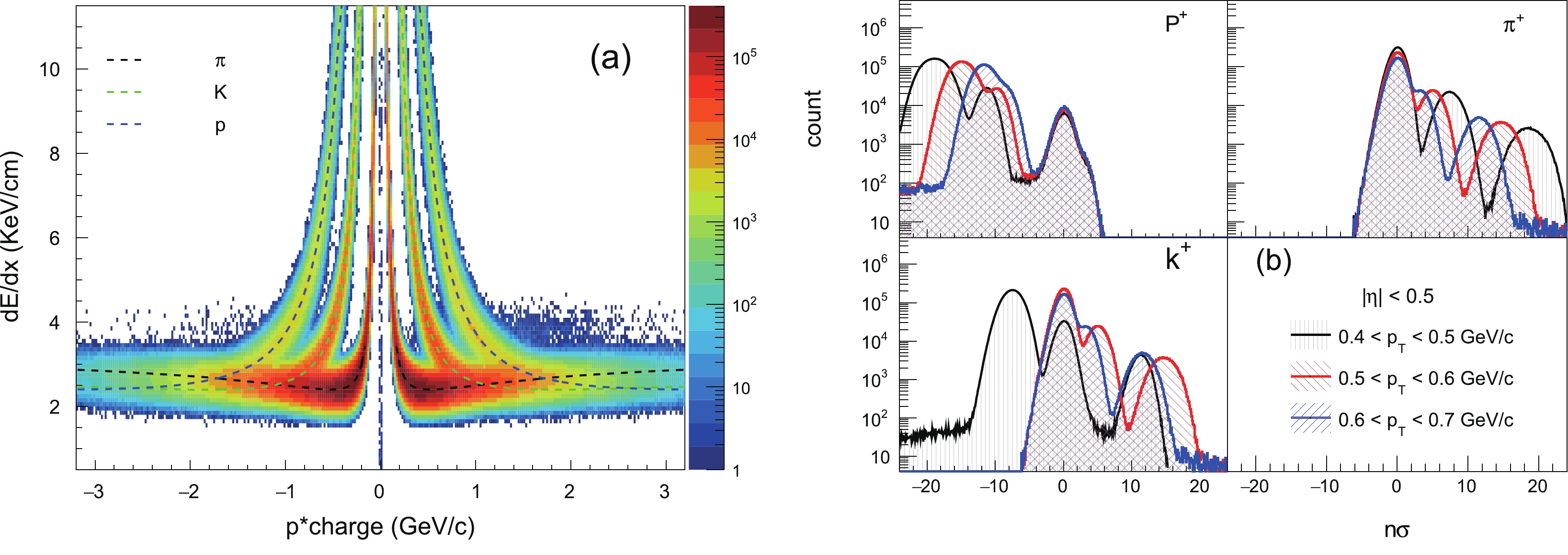
Figure 5. (color online) (a)
${\rm d}E/{\rm d}x$ from UrQMD simulations plotted against charge × momentum of individual particles for Au+Au collisions at$ \sqrt {{s_{\rm{NN}}}}$ = 200 GeV. (b)$ n\sigma$ distributions of protons, pions, and kaons.$ n\sigma_{X} = \frac{1}{R} \ln \frac{[{\rm d}E/{\rm d}x]_{\rm obs}}{[{\rm d}E/{\rm d}x]_{th,X}}, $

(34) where
$[{\rm d}E/{\rm d}x]_{\rm obs}$ represents the energy loss in the UrQMD simulation and$[{\rm d}E/{\rm d}x]_{th,X}$ is the corresponding theoretical value for particle species X. R represents the${\rm d}E/{\rm d}x$ resolution, and we use R = 7.5% within our analysis range. Figure 5(b) presents the$ n\sigma $ distributions of$ p(\bar{p}) $ ,$ \pi^{\pm} $ and$ k^{\pm} $ . Typically,$ n\sigma_{p} < 2 $ are adopted for the$ p(\bar{p}) $ selection. Similarly,$ n\sigma_{\pi} < 2 $ and$ n\sigma_{k} < 2 $ are adopted for pion and kaon selections, respectively. However, from Fig. 5(a), we can deduce that at high momenta, the${\rm d}E/{\rm d}x$ bands for different particles are overlapped. We have also adopted the$ 2\sigma $ -rejection cut to improve the purity.Figure 6 presents the event-by-event average of net-charge, net-kaon, and net-proton multiplicities as a function of
$ n\sigma $ . Similarly, Fig. 7 presents mixed-cumulants as a function of the$ n\sigma $ cut for three cases as follows (refer to Table 1):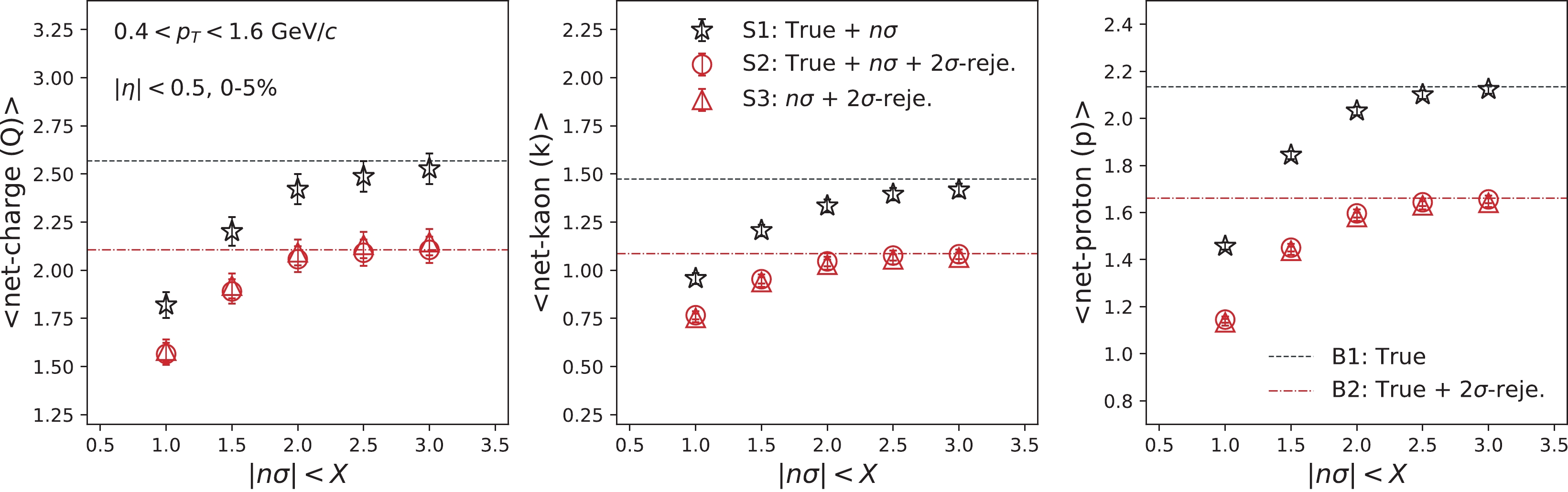
Figure 6. (color online)
$ n\sigma $ acceptance dependence mean multiplicity of net-charge (Q), net-proton (p), and net-kaon (k) for Au+Au collisions at 200 GeV, using the UrQMD model.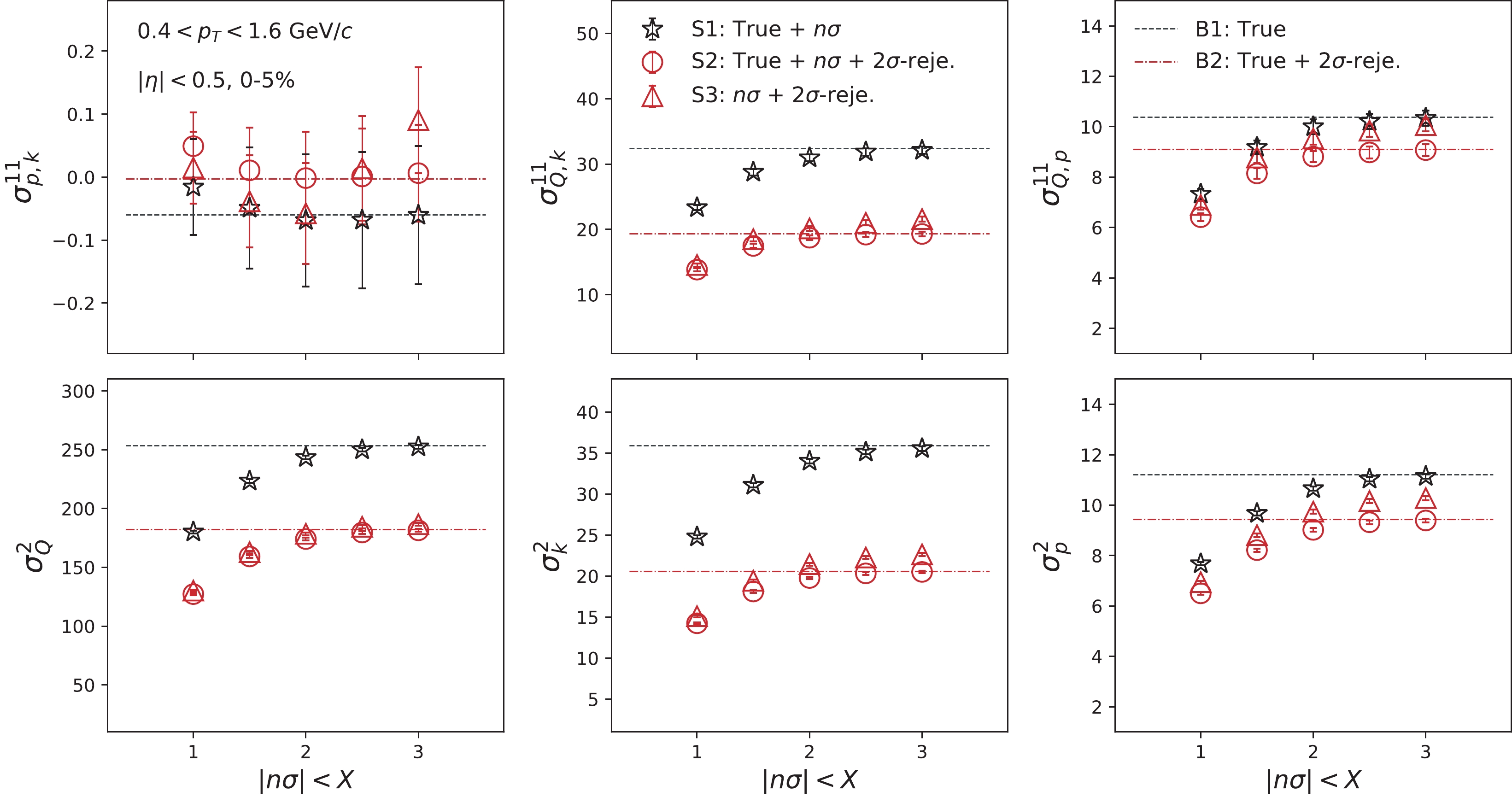
Figure 7. (color online)
$ n\sigma $ acceptance dependence second-order off-diagonal and diagonal cumulants for Au+Au collisions at 200 GeV, using the UrQMD model.For Legend Particle Code $ n\sigma$ 

$ 2\sigma$ -rejection

Baseline Signal S1 Used Applied N/A B1 S2 Used Applied Applied B2 S3 N/A Applied Applied B2 Baseline B1 Used N/A N/A N/A B2 Used N/A Applied N/A Table 1. This table describes the information that is used to select the particles for mixed-cumulant calculations in Fig. 7, in terms of the particle species code given by UrQMD,
$ n\sigma$ , and$ 2\sigma$ -rejection cuts. Corresponding legends in Figs. 6, 7, and 8 are presented in the second left row.S1 : Information on the particle species is provided by UrQMD. The
$ n\sigma $ cut is applied.S2 : Information on the particle species is provided by UrQMD. Both
$ n\sigma $ and$ 2\sigma $ -rejection cuts are applied.S3 : Particles are identified by both
$ n\sigma $ and$ 2\sigma $ -rejection cuts. This is the only possible cut in the experimental data analysis.We note that "Q" is defined as the summation of the identified π, K, and p. The "
$ 2\sigma $ -rejection cut" indicates the requirement of$ n\sigma_{K} > 2.0 $ and$ n\sigma_{\pi}>2.0 $ for proton identification,$ n\sigma_{p}<-2.0 $ and$ n\sigma_{\pi}>2.0 $ for kaon identification, and$ n\sigma_{K}<-2.0 $ and$ n\sigma_{p}<-2.0 $ for pion identification. Furthermore, two baselines are calculated with the following conditions, which are independent of the$ n\sigma $ cut:B1 : Information on the particle species is provided by UrQMD.
B2 : Information on the particle species is provided by UrQMD. The
$ 2\sigma $ -rejection cut is applied.The difference between two baselines is owing to the particle multiplicity. There are more particles for B1 than B2 becuase the
$ 2\sigma $ -rejection cut is applied to the latter case. Depending on whether the$ 2\sigma $ -rejection cut is applied, S1 can be compared to B1, while S2 and S3 need to be compared to B2. The descriptions of Fig. 7 are summarized in Table 1.It is determined that the values of mixed-cumulants are close to the corresponding baselines with a loose
$ n\sigma $ cut, and decreases with the tightening of the$ n\sigma $ cut. As can be observed in Eq. (19), the mixed-cumulant for the mutually inclusive case comprises second-order cumulants, as well as second-order mixed-cumulants. It is well known that the former has a trivial volume dependence [67], which can also be confirmed from the lower panels in Fig. 7 for the second-order cumulants. In Fig. 7, therefore, only$ \sigma^{11}_{p,k} $ is independent of the$ n\sigma $ cut. The difference between S2 and S3 would indicate the effect of contamination. This can be confirmed from the fact that the difference becomes small with the tightening of the$ n\sigma $ cut, in addition to the 2$ \sigma $ -rejection cut. Consequently, we observed larger values of$ \sigma^{11}_{Q,k} $ and$ \sigma^{11}_{Q,p} $ for S3, compared to those for S2.To cancel the trivial volume dependence, the normalized mixed-cumulants are also calculated in Fig. 8 as a function of the
$ n\sigma $ cut. All the results for S1, S2, and S3 are inferred to be consistent with corresponding baselines within uncertainties. This is because the probability of the contamination has been significantly suppressed by the$ 2\sigma $ -rejection cut. To confirm this, normalized mixed-cumulants with only the$ n\sigma $ cuts are calculated, where the significant deviations are observed from the corresponding baselines, owing to contamination. It should be noted that the$ n\sigma $ dependence of mixed-cumulants and normalized mixed-cumulants also depends on how the intrinsic correlations between two variables change relative to the$ n\sigma $ cut. In the current simulation, the energy losses of particles are randomly smeared to implement the resolution of the detectors. Therefore, the correlation terms (the first term on the right hand side of Eqs. (19) and (23)) are considered to be unaffected by the$ n\sigma $ cut. However, experimentally, this effect needs to be carefully studied by changing the criteria for particle identifications.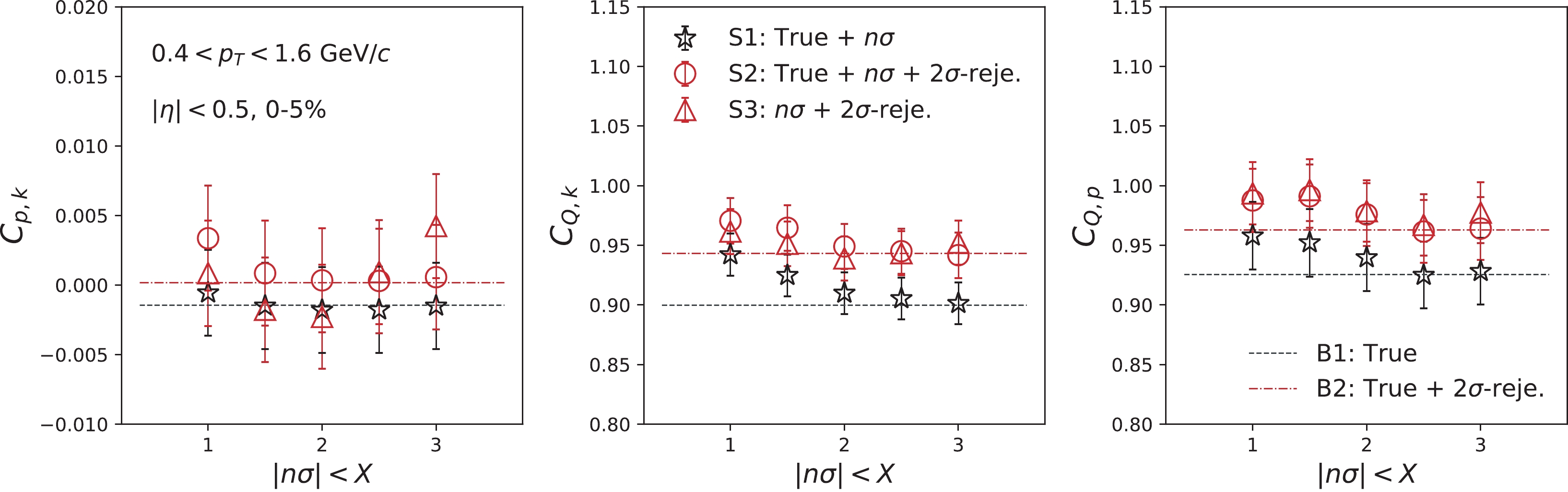
Figure 8. (color online)
$ n\sigma $ acceptance dependence second-order off-diagonal over diagonal cumulant ratios for Au+Au collisions at 200 GeV, using the UrQMD model. -
In this study, we discussed the efficiency correction problem for mixed-cumulants. This study provided a comprehensive extension of the binomial efficiency correction formula for second-order mixed accumulators in two different cases: one case is for mutually exclusive variables and the other is for mutually inclusive variables. We infer that different efficiency correction formulas need to be applied to mixed-cumulants, depending on the type of variable pairs. To apply the binomial efficiency correction for Q-k and Q-p mixed cumulants, it is necessary to identify the charged particles with their corresponding efficiencies.
It should be noted that the efficiency correction for mixed-cumulants in the case of mutually inclusive variables has already been discussed in Ref. [68]. In the proposed formulas, two different levels of efficiencies were implemented for each variable, such as
$ N_{Q} $ and$ N_{p} $ in the case of$ \sigma^{11}_{Q,p} $ . The tracking efficiency was applied to$ N_{Q} $ , while the proton identification efficiency was applied on top of the tracking efficiency for$ N_{p} $ . The method has the advantage that we can keep charged particles as much as possible without identifying each particle species contained in$ N_{Q} $ . This implies that the averaged efficiencies for pions, kaons, and protons were used for$ N_{Q} $ . However, we must remember that using the averaged efficiency does not provide the true solution, which depends on underlying probability distributions of the number of particles and the difference in efficiency between particle species [55]. It is also important to note that the identity method would be useful for the measurements of mixed-cumulants [69], which enables us to measure fluctuations without the multiplicity loss, owing to particle identification. It would be desirable for novel ideas to address the two-step efficiency based on the identity method [69].At this stage, the identification of each particle species and subsequent implemention of the appropriate efficiency is the simplest approach. Therefore, we further investigated the effect of the loss in multiplicity owing to particle identifications, using numerical simulations. In the case of mutually inclusive variables, the mixed-cumulants exhibited a monotonic decrease as the cut value of particle identification tightened. This can be explained by a trivial volume dependence. In contrast, the normalized mixed-cumulants were determined to be independent of the cut value for the particle identification. This is because the intrinsic correlations between different particle species were assumed to be independent of the variables of the particle identification, which could not be the case in real experiments. Therefore, it is recommended to verify these effects by changing the criteria for the particle identifications. This work provides an important reference for future measurements of mixed-cumulants in relativistic heavy-ion collisions.
-
We thank Volker Koch, Masakiyo Kitazawa, Nihar Rajan Sahoo, Prithwish Tribedy, Volodymyr Vovchenko, Tapan Nayak, and Nu Xu for stimulating discussions.
-
The efficiency correction formulas for higher-order mixed-cumulants are provided in Ref. [55] as
$ \tag{A1} \begin{aligned}[b] {\langle\!\langle{ K_{(x)}^2K_{(y)} }\rangle\!\rangle} _{\rm{c}} =& {\langle{\kappa{(1,0,1)}^{2}\kappa{(0,1,1)}}\rangle} _{\rm{c}} + 2{\langle{\kappa{(1,0,1)}\kappa{(1,1,1)}}\rangle} _{\rm{c}} - 2{\langle{\kappa{(1,0,1)}\kappa{(1,1,2)}}\rangle} _{\rm{c}} \\ & + {\langle{\kappa{(0,1,1)}\kappa{(2,0,1)}}\rangle} _{\rm{c}} - {\langle{\kappa{(0,1,1)}\kappa{(2,0,2)}}\rangle} _{\rm{c}} + {\langle{\kappa{(2,1,1)}}\rangle} _{\rm{c}} -3{\langle{\kappa{(2,1,2)}}\rangle} _{\rm{c}} + 2{\langle{\kappa{(2,1,3)}}\rangle} _{\rm{c}}, \end{aligned} $ 
$ \tag{A2} \begin{aligned}[b] {\langle\!\langle{ K_{(x)}^2K_{(y)}^2 }\rangle\!\rangle} _{\rm{c}} = &{\langle{\kappa{(1,0,1)}^{2}\kappa{(0,1,1)}^{2}}\rangle} _{\rm{c}} + {\langle{\kappa{(1,0,1)}^{2}\kappa{(0,2,1)}}\rangle} _{\rm{c}} - {\langle{\kappa{(1,0,1)}^{2}\kappa{(0,2,2)}}\rangle} _{\rm{c}} + {\langle{\kappa{(0,1,1)}^{2}\kappa{(2,0,1)}}\rangle} _{\rm{c}} \\ & - {\langle{\kappa{(0,1,1)}^{2}\kappa{(2,0,2)}}\rangle} _{\rm{c}} +4{\langle{\kappa{(1,0,1)}\kappa{(0,1,1)}\kappa{(1,1,1)}}\rangle} _{\rm{c}} -4{\langle{\kappa{(1,0,1)}\kappa{(0,1,1)}\kappa{(1,1,2)}}\rangle} _{\rm{c}} \\ & +2{\langle{\kappa{(1,0,1)}\kappa{(1,2,1)}}\rangle} _{\rm{c}} -6{\langle{\kappa{(1,0,1)}\kappa{(1,2,2)}}\rangle} _{\rm{c}} +4{\langle{\kappa{(1,0,1)}\kappa{(1,2,3)}}\rangle} _{\rm{c}} \\ & +2{\langle{\kappa{(0,1,1)}\kappa{(2,1,1)}}\rangle} _{\rm{c}} -6{\langle{\kappa{(0,1,1)}\kappa{(2,1,2)}}\rangle} _{\rm{c}} +4{\langle{\kappa{(0,1,1)}\kappa{(2,1,3)}}\rangle} _{\rm{c}} \\ & -4{\langle{\kappa{(1,1,1)}\kappa{(1,1,2)}}\rangle} _{\rm{c}} +2{\langle{\kappa{(1,1,1)}^{2}}\rangle} _{\rm{c}} +2{\langle{\kappa{(1,1,2)}^{2}}\rangle} _{\rm{c}} \\ & + {\langle{\kappa{(2,0,1)}\kappa{(0,2,1)}}\rangle} _{\rm{c}} - {\langle{\kappa{(2,0,1)}\kappa{(0,2,2)}}\rangle} _{\rm{c}} - {\langle{\kappa{(2,0,2)}\kappa{(0,2,1)}}\rangle} _{\rm{c}} + {\langle{\kappa{(2,0,2)}\kappa{(0,2,2)}}\rangle} _{\rm{c}} \\ & + {\langle{\kappa{(2,2,1)}}\rangle} _{\rm{c}} -7{\langle{\kappa{(2,2,2)}}\rangle} _{\rm{c}} +12{\langle{\kappa{(2,2,3)}}\rangle} _{\rm{c}} -6{\langle{\kappa{(2,2,4)}}\rangle} _{\rm{c}}, \end{aligned} $

$ \tag{A3} \begin{aligned}[b] {\langle\!\langle{ K_{(x)}^3 K_{(y)} }\rangle\!\rangle} _{\rm{c}} =& {\langle{\kappa{(1,0,1)}^{3}\kappa{(0,1,1)}}\rangle} _{\rm{c}} +3{\langle{\kappa{(1,0,1)}^{2}\kappa{(1,1,1)}}\rangle} _{\rm{c}} -3{\langle{\kappa{(1,0,1)}^{2}\kappa{(1,1,2)}}\rangle} _{\rm{c}} +3{\langle{\kappa{(2,0,1)}\kappa{(1,0,1)}\kappa{(0,1,1)}}\rangle} _{\rm{c}} \\ & -3{\langle{\kappa{(2,0,2)}\kappa{(1,0,1)}\kappa{(0,1,1)}}\rangle} _{\rm{c}} +3{\langle{\kappa{(1,0,1)}\kappa{(2,1,1)}}\rangle} _{\rm{c}} -9{\langle{\kappa{(1,0,1)}\kappa{(2,1,2)}}\rangle} _{\rm{c}} \\ & +6{\langle{\kappa{(1,0,1)}\kappa{(2,1,3)}}\rangle} _{\rm{c}} +3{\langle{\kappa{(2,0,1)}\kappa{(1,1,1)}}\rangle} _{\rm{c}} -3{\langle{\kappa{(2,0,1)}\kappa{(1,1,2)}}\rangle} _{\rm{c}} -3{\langle{\kappa{(2,0,2)}\kappa{(1,1,1)}}\rangle} _{\rm{c}} \\ & +3{\langle{\kappa{(2,0,2)}\kappa{(1,1,2)}}\rangle} _{\rm{c}} + {\langle{\kappa{(3,0,1)}\kappa{(0,1,1)}}\rangle} _{\rm{c}} -3{\langle{\kappa{(3,0,2)}\kappa{(0,1,1)}}\rangle} _{\rm{c}} +2{\langle{\kappa{(3,0,3)}\kappa{(0,1,1)}}\rangle} _{\rm{c}} \\& + {\langle{\kappa{(3,1,1)}}\rangle} _{\rm{c}} -7{\langle{\kappa{(3,1,2)}}\rangle} _{\rm{c}} +12{\langle{\kappa{(3,1,3)}}\rangle} _{\rm{c}} -6{\langle{\kappa{(3,1,4)}}\rangle} _{\rm{c}}. \end{aligned} $

The substitution of appropriate indices for x and y in Eq. (15) is required, as discussed in Sec. II.
Efficiency corrections for mutually inclusive variables and particle identification effect for mixed-cumulants in heavy-ion collisions
- Received Date: 2021-05-27
- Available Online: 2021-10-15
Abstract: Mix-cumulants of conserved charge distributions are sensitive observables for probing properties of the QCD medium and phase transition in heavy-ion collisions. To perform precise measurements, efficiency correction is one of the most important step. In this study, using the binomial efficiency model, we derive efficiency correction formulas for mutually exclusive and inclusive variables. The UrQMD model is applied to verify the validity of these formulas for different types of correlations. Furthermore, we investigate the effect of the multiplicity loss and contamination emerging from the particle identifications. This study provides important steps toward future measurements of mixed-cumulants in relativistic heavy-ion collisions.



 DownLoad:
DownLoad: